블로그
 100% 안전 | Mac 버전으로 가기 >>
100% 안전 | Linux 버전으로 가기>>
100% 안전 | Windows 버전으로 가기 >>
100% 안전 | ios 버전으로 가기 >>
100% 안전 | android 버전으로 가기 >>
100% 안전 | Mac 버전으로 가기 >>
100% 안전 | Linux 버전으로 가기>>
100% 안전 | Windows 버전으로 가기 >>
100% 안전 | ios 버전으로 가기 >>
100% 안전 | android 버전으로 가기 >>
제 1부: 히스토그램이란?
히스토그램은 서로 다른 높이와 너비의 막대를 사용하여 데이터를 통계적으로 근사화하는데 도움됩니다. 히스토그램은 연속형 데이터를 사용자 지정 범위로 응축하여 분포를 나타냅니다. 즉, 정보를 보다 효율적으로 전달할 수 있도록 많은 양의 데이터를 읽기 쉬운 그래프로 요약합니다.
제 2부: 히스토그램의 역사
히스토그램이라는 용어는 그리스 어의 기원으로 19세기 말에 영국의 유명한 수학자이자 생물 통계학자인 칼 피어슨에 의해 그래픽 표현의 일반적인 형태를 가리키기 위해 처음 사용되었습니다. 즉, 그가 히스토그램을 소개한 것으로 알려져 있습니다.
이것은 칼이 이 차트를 발명한 것은 아니라는 것을 의미합니다. 그리고 히스토그램은 이러한 이름을 얻기 훨씬 이전에 사용되었습니다. 하지만 그 날짜와 유래는 여전히 불분명합니다. 그럼에도 불구하고 칼의 이름을 붙인 이후로 이 차트는 더 인기를 끌었고, 연구자들과 분석가들 사이에서 인정을 받기 시작했습니다.
제 3부: 왜 히스토그램을 사용할까요?
히스토그램은 데이터 분포를 시각적으로 나타내기 위한 중요 도구입니다. 이 차트는 대량의 데이터를 요약하고 값의 빈도를 나타냅니다. 따라서 데이터 분포 추세와 중앙값을 결정하는데 도움이 됩니다. 또한 데이터의 간격과 특이치를 강조하는 데에도 효과적입니다.
제 4부: 히스토그램을 언제 사용해야 하나요?
히스토그램은 다음 작업을 수행할 때 사용할 수 있습니다.
- 데이터 열의 값 분포를 표시합니다.
- 큰 데이터 값을 작은 그래픽으로 표현하여 압축합니다.
- 프로세스 결과를 특정 제한과 비교하여 요구사항을 충족하는지 여부를 파악합니다.
- 두 개 이상의 프로세스 출력을 비교합니다.
- 공정의 출력에 따라 결정을 내립니다.
제 5부: 히스토그램의 주요 요소
히스토그램은 다음과 같은 네 가지 주요 구성 요소로 이루어집니다.
1. 제목
히스토그램에 포함된 정보를 표시합니다.
2. 가로 축(X축)
데이터가 분할된 구간을 나타냅니다. 구간은 균일하며 많은 데이터 세트를 요약하는 데 도움이 됩니다. 개별 데이터 값은 표시되지 않습니다.
3. 세로 축(Y축)
Y축은 데이터 그래프의 빈도를 나타내며, 이는 해당 구간에서 값이 발생한 횟수입니다.
4. 막대
막대에는 변수 높이와 너비가 있으며 데이터 그림을 나타내는 데 사용됩니다. 높이는 값의 빈도에 해당하며 너비는 구간의 길이를 나타냅니다.
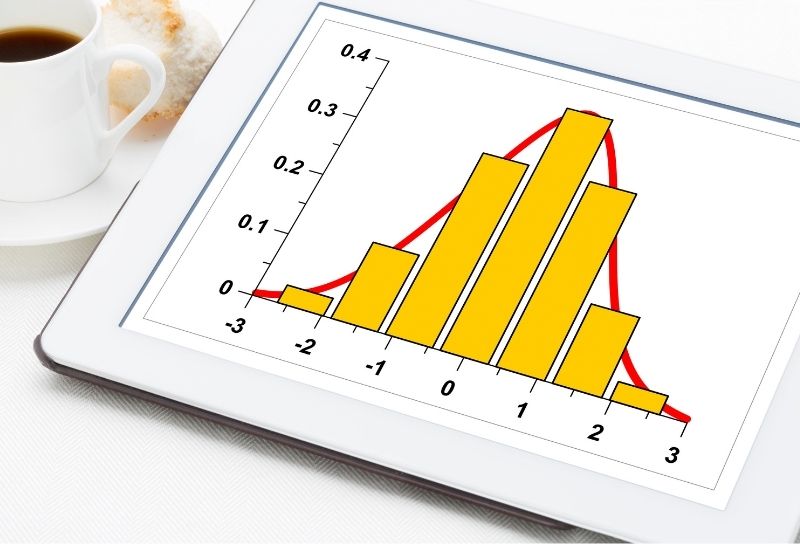
제 6부: 히스토그램의 분포
히스토그램은 빈도 분포를 표시하는 데 중요한 도구이며, 각 집합에서 값이 얼마나 반복되는지 보여줍니다. 아래에는 데이터의 서로 다른 분포를 나타내는 몇 가지 일반적인 히스토그램 모양이 나와 있습니다.
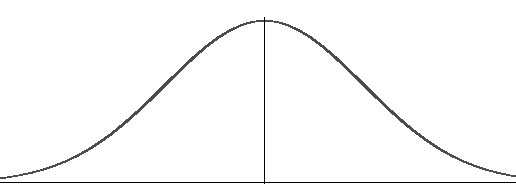
1. 기본 분포
종 모양의 곡선 그래프는 정규 분포를 나타내는 데 사용됩니다. 평균의 한쪽에 있는 점이 다른 쪽에 있을 가능성이 높기 때문에 그래프의 모양이 매우 대칭적입니다.
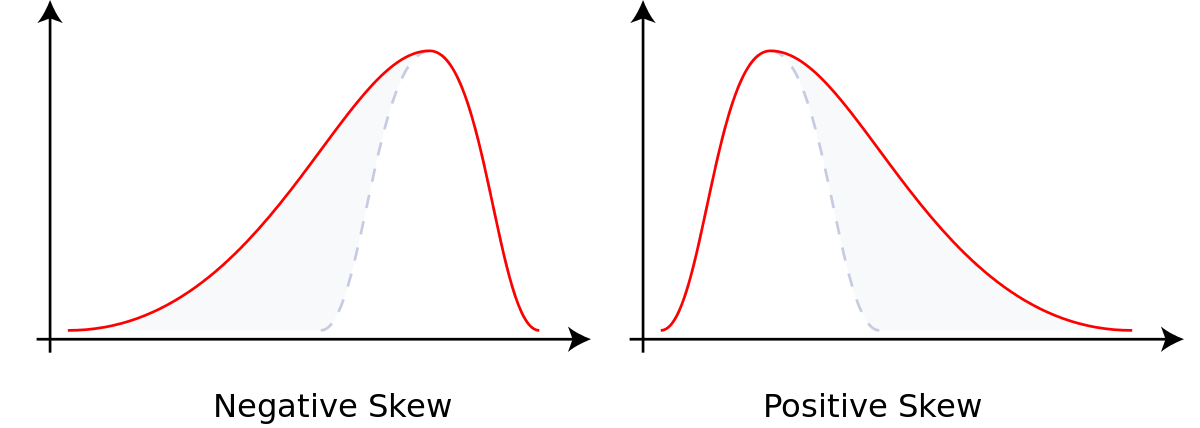
2. 사선형 분포
In a skewed distribution, the peak is inclined towards the limit, and a tail proceeds away from it. It is an asymmetrical distribution that can be skewed to the right or left. While the right skew distribution is termed positively skewed, a distribution skewed to the left is negative. We get a right-skewed distribution if all the collected data has a value greater than zero, whereas the left-skewed is formed when data has values less than 100.
3. 불규칙 분포
이름에서 알 수 있듯이, 이 분포 유형은 랜덤 패턴을 나타내며 여러 개의 분산 피크를 가집니다. 히스토그램이 이 모양을 나타내는 경우, 서로 다른 프로세스가 결합되었음을 의미하며 각 프로세스를 개별적으로 분석하는 방법을 결정할 수 있습니다.
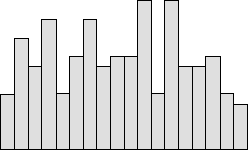
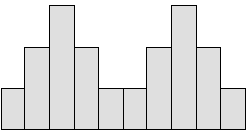
4. 비모달 분포
이중 피크 그래프라고도 하는 이 모달 분포는 서로 다른 두 프로세스의 데이터가 병합되어 하나의 데이터 세트를 형성했음을 나타냅니다. 이러한 경우 두 프로세스의 데이터를 별도로 분석해야 합니다.
제 7부: 기본적인 히스토그램을 만드는 방법은?
1 단계:프로세스를 위한 데이터 값을 수집합니다.
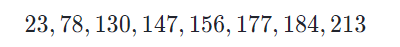
2 단계:이제 각 막대에 적합한 너비를 결정합니다. 범위는 구간이 동일해야 하며 모든 데이터에 적합해야 합니다.
3 단계:히스토그램의 막대 수를 선택합니다. 계급구간이 너무 많거나 너무 적으면 안 됩니다.
4 단계:각 계급구간에 포함되는 값의 수를 확인하여 데이터 플롯에 대한 빈도 분포도를 만듭니다.
5 단계:그래프를 그리고 축에 레이블을 지정합니다. 2단계에서 선택한 간격과 y축을 데이터 값 의 빈도로 축을 조정합니다.
6 단계:각 간격별로 막대 그래프를 그리므로 막대가 각 값의 빈도와 일치합니다. 막대 사이에 공백이 없어야 합니다.
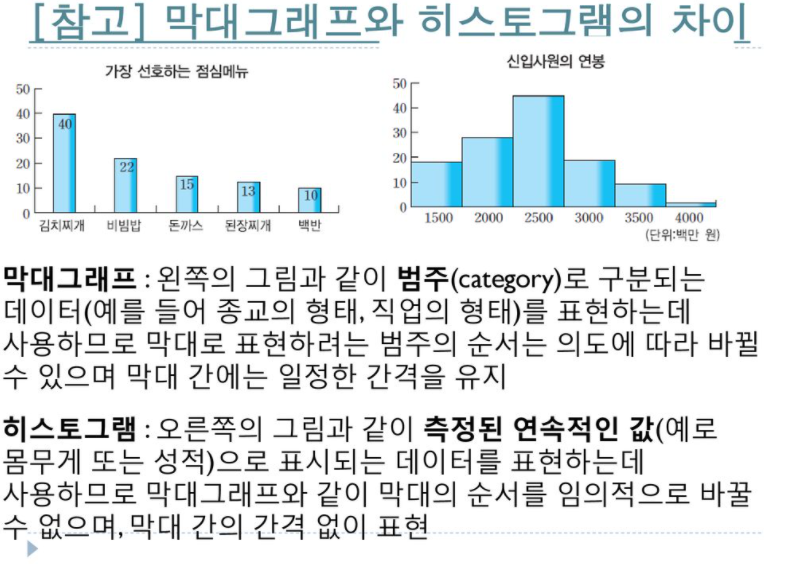
제 8부: 히스토그램 Vs 막대 그래프
사람들은 종종 히스토그램이 바 그래프의 일종이라고 주장합니다. 그러나 사실이 아닙니다. 비슷하게 보일 수는 있지만 두 개의 다른 그래프 형태입니다.
제 9부: 히스토그램 예시
히스토그램을 더 잘 이해하기 위하여 아래에 주어진 몇 가지 예를 살펴보겠습니다.
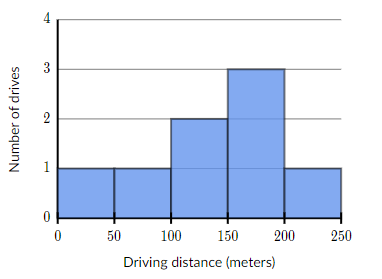
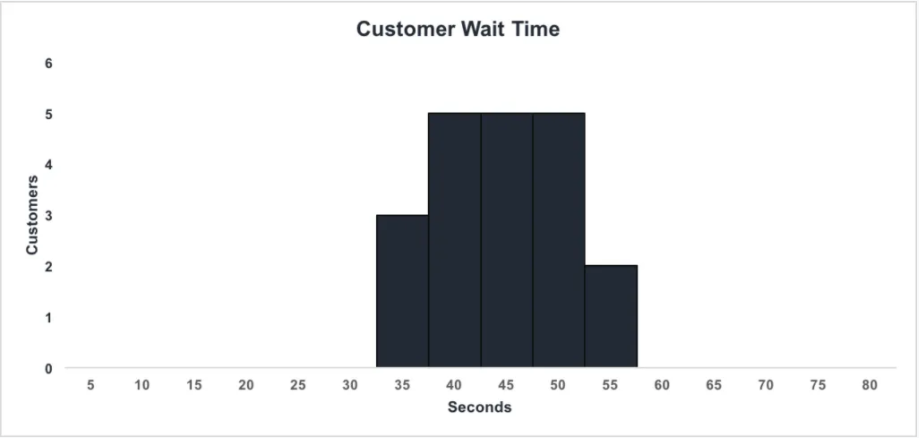
1. 고객 대기 시간
이것은 특정 장소에서 고객이 경험한 대기 시간을 플롯한 히스토그램입니다. 데이터를 수집한 다음 모든 값에 맞게 적절한 간격으로 분할했습니다. 히스토그램을 통해 3명의 고객이 35초 동안 기다린 반면, 5명은 최소 50초 동안 대기했다는 것을 쉽게 해석할 수 있습니다. 이러한 그래프는 시스템의 효율성을 확인하고 서비스를 개선하는 좋은 방법입니다.
2. 체리 나무의 높이
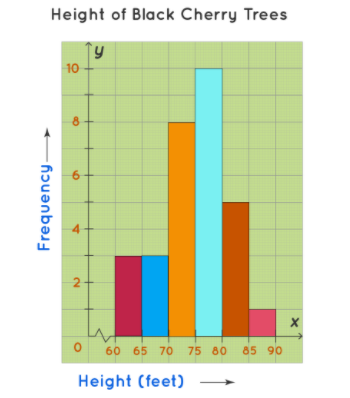
이것은 과수원에서 벚꽃나무의 높이에 관한 히스토그램을 플롯한 또 다른 예입니다. 과수원에는 30그루의 나무가 있었고, 높이는 각각에 대해 측정되었습니다. 그런 다음 데이터는 간격을 설정하고 빈도를 기록하는 빈도 분포 차트의 형태로 그룹화됩니다.
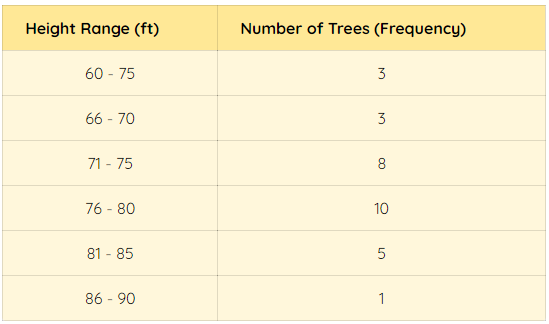
데이터에 대한 히스토그램은 과수원의 대부분의 나무가 75-80 피트 높이임을 명확하게 보여줍니다. 그래프는 이해하기 쉽고, 과수원에서 나무의 높이 분포를 결정하는 데 도움이 됩니다.
제 9부: 결론
끝입니다! 여러분이 히스토그램에 대하여 알고 싶었던 모든 궁금증이 풀렸기를 바랍니다.히스토그램은 데이터를 시각적으로 즐겁고 창의적인 방법으로 요약하여 당신의 프레젠테이션 기술을 크게 향상시킬 수 있습니다. 히스토그램을 만드는 것은 간단하긴 하지만 Edraw Max를 사용하면 훨씬 더 간단해집니다. 다양한 툴과 사용자 친화적인 인터페이스가 당신의 창의력을 빠르게 펼칠 수 있도록 도와줄 것입니다.
이드로우맥스
올인원 다이어그램 소프트웨어
순서도, 평면도, 회로도 등 280가지 이상의 다이어그램 유형 지원
2만6천개 이상의 기호 리소스와 수 천개 무료 템플릿 지원
- 강력한 호환성: Visio,MS office 등 파일 호환 가능
- 다양한 운영체제: (윈도우,맥,리눅스,ios,android)
관련 글