
Il software OCR (riconoscimento ottico dei caratteri) ti consente di estrarre testo da diverse fonti, che si tratti di documenti scannerizzati, immagini o PDF. Ora, parliamo dei vantaggi per gli utenti di Linux. Pensa a diventare più produttivo e automatizzare compiti ripetitivi. Gli strumenti OCR per Linux possono aiutarti a digitalizzare facilmente i documenti per analizzarne, modificarne e cercarne il contenuto.
Sei curioso di sapere quale strumento OCR per Linux si distingue dagli altri? Nel nostro prossimo manuale, imparerai le migliori 7 opzioni, considerando le loro caratteristiche, facilità d'uso e svantaggi. La maggior parte degli strumenti offre interfacce a riga di comando e grafiche che soddisfano sia gli esperti di scripting che gli utenti occasionali. Esplora e trova la migliore soluzione OCR per Linux che si adatti alle tue competenze e al tuo flusso di lavoro.
In questo articolo
- Wondershare EdrawMind: AI OCR per il brainstorming
- Tesseract: motore OCR open-source per Linux
- CiaoPDF: OCR online facile da usare per Linux
- GOCR: Strumento OCR leggero e veloce per Linux
- Adobe Acrobat: Editor professionale di PDF e strumento OCR
- CuneiForm: Sistema OCR multilingue gratuito
- OCRmyPDF: Potente strumento da riga di comando
Wondershare EdrawMind: AI OCR per il brainstorming
Per gli utenti che cercano il miglior OCR per Linux all'interno di una mappa mentale, Wondershare EdrawMind offre un'opzione convincente. Integra in modo fluido una robusta funzionalità OCR, che ti consente di convertire le immagini in testo modificabile all'interno delle tue mappe mentali. Non c'è bisogno di cambiare applicazioni o combattere con le righe di comando. Perfetto per il brainstorming visivo o la pianificazione dei progetti, lo strumento OCR di EdrawMind per Linux ti permette di organizzare e analizzare le informazioni come mai prima d'ora.
 100% sicuro | Nessuna pubblicità |100% sicuro | Versioni per desktop >>
100% sicuro | Nessuna pubblicità |100% sicuro | Versioni per desktop >>Ecco come utilizzare EdrawMind OCR:
Passo 1: Vai alla scheda AI nella barra di navigazione superiore, quindi clicca su Estrazione testo da immagine per aprire la finestra OCR.
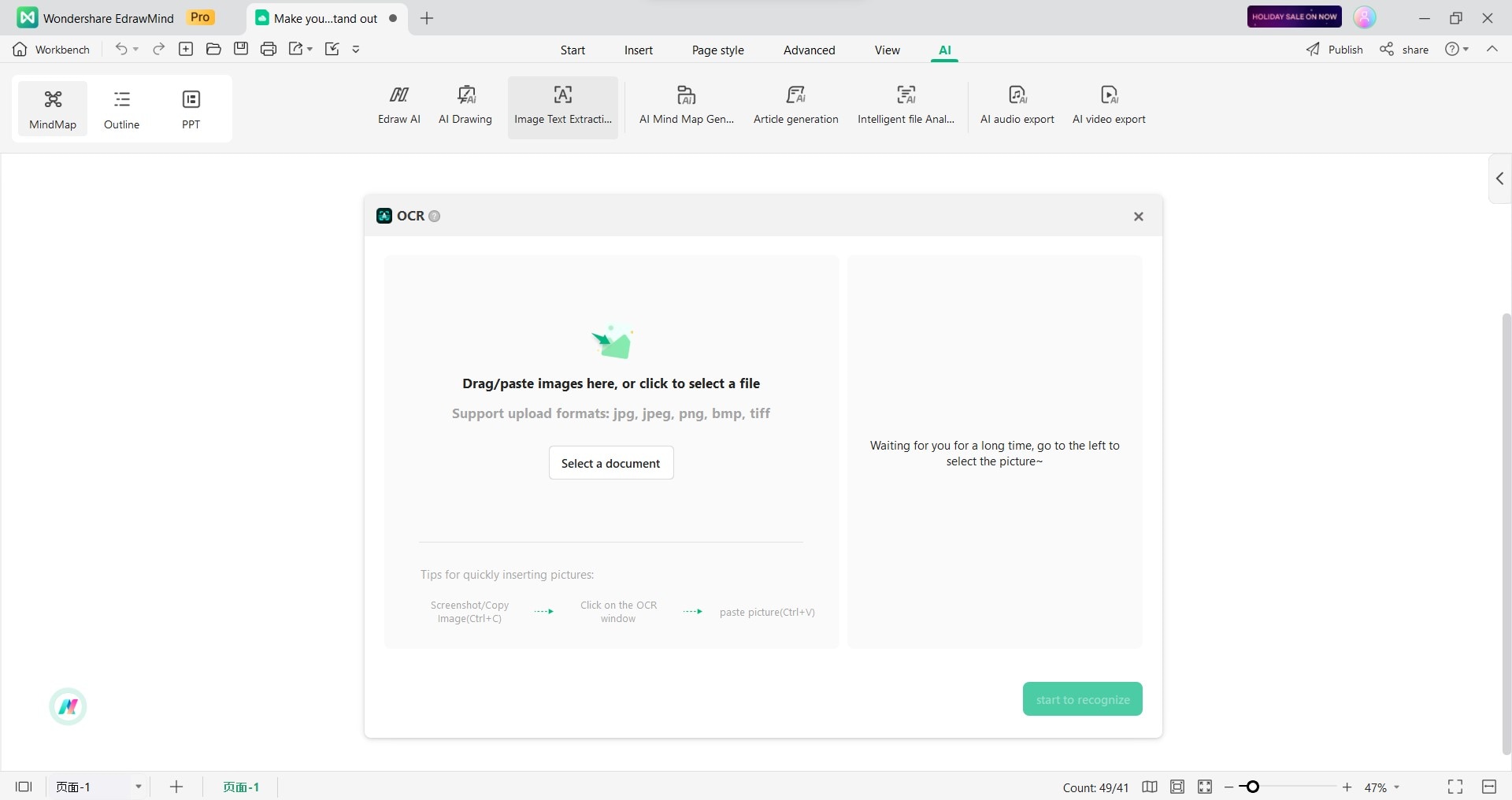
Passo 2: Nella finestra OCR che appare, fare clic su Seleziona un documento e scegliere il file immagine contenente il testo che si desidera estrarre.
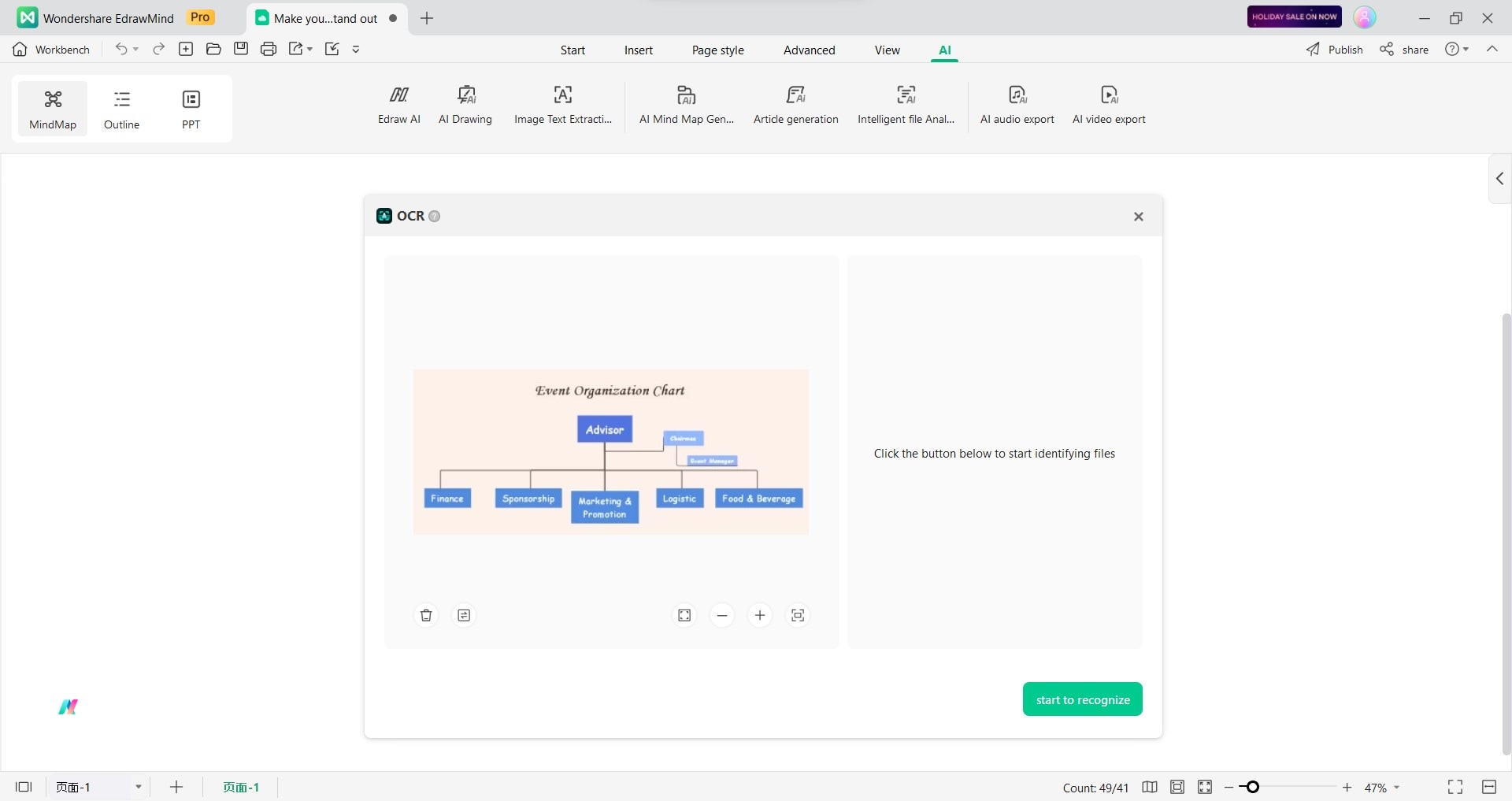
Passo 3: Una volta importata l'immagine, fare clic su avvia riconoscimento.
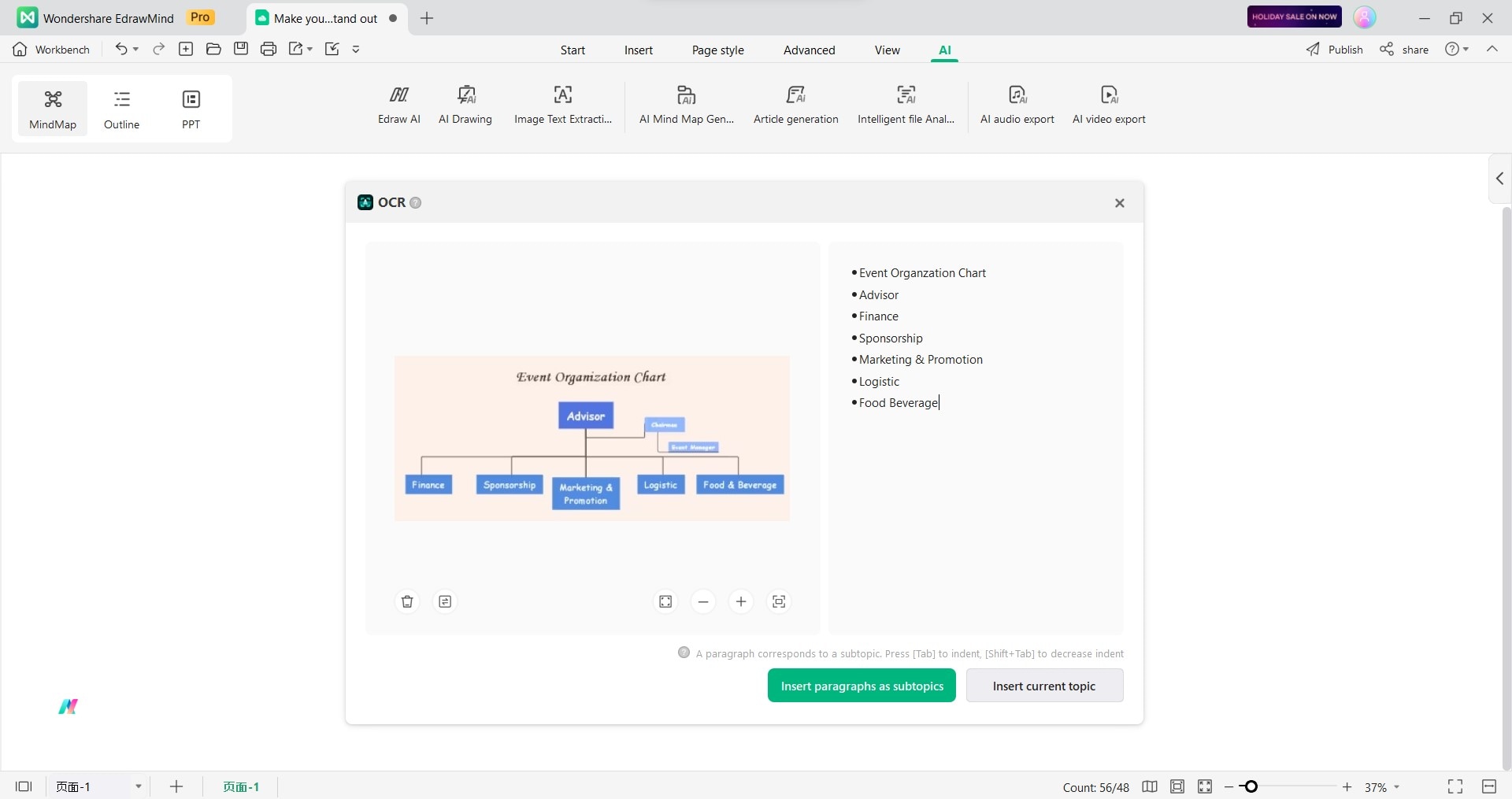
Passo 4: Vedrai il testo estratto nella finestra OCR dopo il riconoscimento. Puoi modificare il testo come necessario, correggendo eventuali errori o aggiustando la formattazione.
Passo 5: Creare una mappa mentale con il testo:
- Clicca su Inserisci paragrafi come sottotitoli per aggiungere ciascun paragrafo come un sottotitolo separato.
- Fare clic su Inserisci argomento attuale per aggiungere tutto il testo come un singolo argomento.
Tesseract: motore OCR open-source per Linux
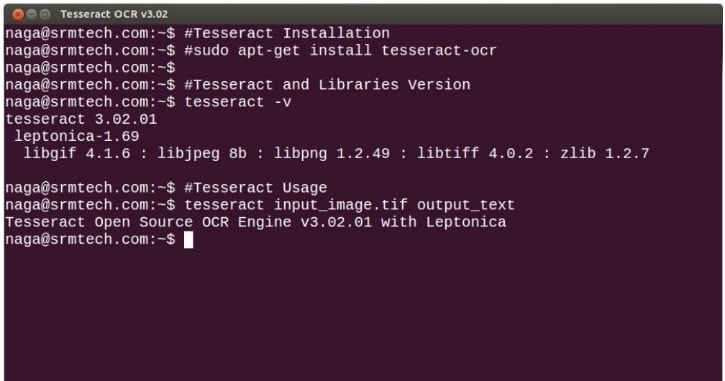
Tesseract, un motore gratuito e open-source, si distingue come software OCR per Linux. A differenza di molti software OCR commerciali, Tesseract ti offre un controllo completo e personalizzazione, direttamente o tramite un'API. Nessuna sottoscrizione costosa o funzionalità bloccate. Questo potente motore supporta oltre 100 lingue e diversi formati di output, inclusi testo semplice e PDF ricercabili.
E la parte migliore? La versione più recente di Tesseract, la 4.0, alza l'asticella con un'innovativa integrazione dell'IA che cambierà il gioco. Utilizza reti neurali LSTM per migliorare l'accuratezza del riconoscimento del testo, specialmente su documenti con dimensioni e layout variabili.
HiPDF: OCR online facile da usare per Linux
HiPDF offre una soluzione OCR basata su cloud accessibile da qualsiasi browser, anche da Linux. Questo approccio evita i problemi di installazione e garantisce l'accesso agli ultimi motori OCR. Rispetto ad altri OCR online per Linux, HiPDF si distingue per il suo supporto multilingue, la capacità di gestire PDF di grandi dimensioni e l'estrazione accurata del testo anche da layout complessi.
Per gli utenti Linux in cerca di un modo rapido e semplice per estrarre testo da immagini scannerizzate e PDF senza dover fare affidamento su software locale, HiPDF è uno dei migliori strumenti OCR per Linux. Il suo principale vantaggio risiede nelle sue caratteristiche, come il mantenimento della formattazione e dei layout, rendendolo ideale per preservare la struttura originale.
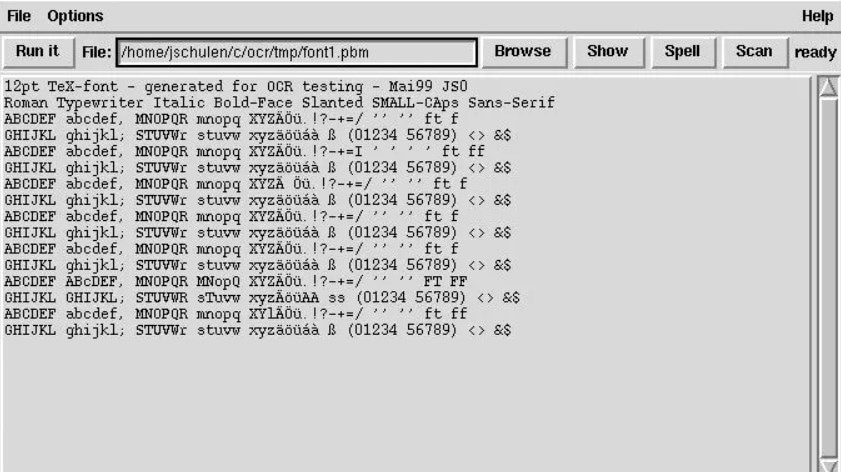
GOCR: Strumento OCR leggero e veloce per Linux
Per gli utenti in cerca di una soluzione OCR Linux gratuita e leggera, GOCR si distingue dalla massa. A differenza delle opzioni commerciali più esigenti, GOCR si avvia da riga di comando, rendendolo efficiente e leggero sulle risorse. Questo programma OCR per Linux può convertire immagini acquisite di testo in file di testo modificabili. GOCR può anche tradurre codici a barre, il che lo distingue da altre opzioni.
Anche se strumenti più recenti basati sull'IA affermano di avere una maggiore precisione, la semplicità e la natura open-source di GOCR lo rendono un compagno affidabile per compiti di estrazione di testo, il tutto all'interno dell'ambiente familiare del terminale. GOCR semplifica l'estrazione del testo con la sua funzionalità autonoma, eliminando la necessità di ulteriore formazione o archiviazione dei font.
Adobe Acrobat: Editor professionale di PDF e strumento OCR
Adobe Acrobat OCR eccelle nel trasformare i PDF scannerizzati in documenti modificabili e ricercabili, all'altezza di altre opzioni popolari. A differenza di molti strumenti per Linux che possono eseguire l'OCR dei file PDF, Adobe Acrobat può mantenere la formattazione e il layout originali mentre estrae il testo modificabile. Questo significa che puoi evitare di ricreare la struttura del documento, risparmiando tempo e sforzi.
Adobe Acrobat OCR è conveniente per gli utenti Linux che lavorano con i PDF nel loro ambiente Ubuntu. Non c'è più bisogno di combattere con la riga di comando: Acrobat gestisce tutto all'interno del suo familiare flusso di lavoro. Le sue avanzate capacità di precisione e riconoscimento del linguaggio garantiscono conversioni di alta qualità, anche per documenti complessi.
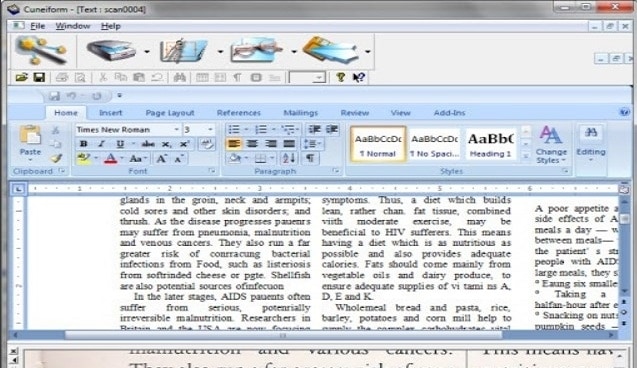
CuneiForm: Sistema OCR multilingue gratuito
CuneiForm si distingue per il suo approccio unico nel mantenere la struttura e la formattazione dei documenti. Mentre la maggior parte delle opzioni di OCR PDF per Linux si concentra esclusivamente sull'estrazione del testo, CuneiForm analizza il layout e i formati del testo. Si assicura che il documento convertito sia quasi identico all'originale. Indipendentemente dal formato della tabella, il programma riconosce e interpreta i dati tabulari.
Puoi modificare i risultati di questo sistema OCR Linux utilizzando i tuoi strumenti preferiti come Word, Notepad o altri editor di testo. La capacità di salvare in formati popolari garantisce la compatibilità e consente ricerche di testo complete.
OCRmyPDF: Potente strumento da riga di comando
Se sei su Ubuntu e stai cercando un PDF OCR, strumenti come OCRmyPDF possono aiutare il tuo flusso di lavoro. Questo strumento open-source aggiunge uno strato di testo ricercabile ai documenti scannerizzati, rendendo il loro contenuto accessibile per la modifica, la ricerca e la selezione. OCRmyPDF utilizza motori OCR avanzati, ottimizzando il processo sia per la velocità che per l'accuratezza.
Integra anche passaggi di pre-elaborazione e post-elaborazione intelligenti per garantire risultati ottimali. Goditi un'esperienza di installazione senza intoppi con la comoda configurazione in una sola riga. Sperimenta la vera potenza dell'estrazione del testo PDF con OCRmyPDF.

Conclusione
La scelta del miglior Linux OCR dipende dalle tue esigenze. Per un rapido processo online, HiPDF eccelle. Per il brainstorming avanzato con l'IA, EdrawMind eccelle. Per velocità ed efficienza, GOCR domina. Per la modifica professionale, Adobe Acrobat è la soluzione ideale. Tesseract, la leggenda open-source, offre flessibilità e personalizzazione.
CuneiForm affronta diverse lingue, mentre OCRmyPDF offre funzionalità avanzate agli utenti della riga di comando. Alla fine, il miglior OCR per Linux è quello che si integra perfettamente con il tuo flusso di lavoro e offre l'accuratezza che richiedi. Quindi, esplora, sperimenta e trova la tua combinazione perfetta con questa guida.
